
Two weeks ago, a UK software developer spotted fuel stations plotted in the Indian Ocean and electric vehicle statistics that had dropped by a factor of 1,000 overnight. Both datasets were published by government bodies and major institutions. Both had glaring, obvious errors that five minutes of validation would have caught. Neither was corrected until public embarrassment forced the issue.
Dispatch
LONDON, 29 MARCH 2026 — The problem surfaces cleanest through a developer's eye. On Successful Software, a platform focused on data wrangling tools, the author (a practitioner, not a polemicist) documented two institutional failures that reveal a systemic collapse in data governance:
A quick plot of the latitude and longitude shows some clear outliers… some of these UK fuel stations are apparently located in the Indian and South Atlantic oceans. In at least one case, it looks like they got the latitude and longitude the wrong way around.
The same dataset showed fuel price ratios of 1,538:1 between the most expensive and cheapest litre — a number that defies physical reality and basic sanity-checking.
Successful Software, 29 March 2026 [1]
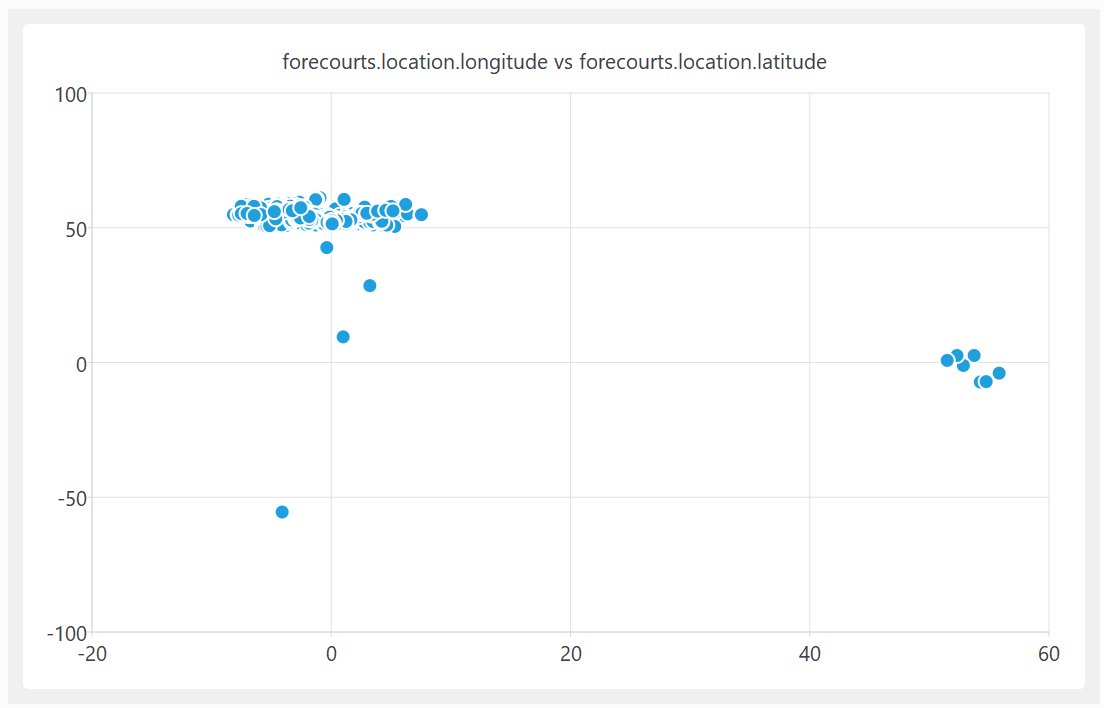
The UK government's fuel finder data — a downloadable CSV file intended as a public resource during Middle East fuel supply tensions — had been live for weeks. The developer reported the errors on 22 March. The government acknowledged receipt on 24 March. By 29 March, the same corrupted file remained published without correction. [1]
The second case compounds the indictment. The RAC (Royal Automobile Club), a major UK motoring organisation, published a report on electric vehicles. Its opening graph showed battery electric vehicles on UK roads plummeting from 1.4 million in 2024 to 0.0017 million in 2025 — a collapse of 99.9 per cent. [1]
Did the number of Battery Electric Vehicles on the UK's roads suddenly drop from ~1.4 million in 2024 to ~0.0017 million in 2025? What happened to those ~1.4 million vehicles? I'm guessing that someone got their thousands and millions mixed up.
Successful Software, 29 March 2026 [1]
The error is elementary. Thousands and millions are not interchangeable. The actual EV fleet has grown, not evaporated. Yet the report circulated with this error embedded in its headline visual.
A parallel concern emerges from Guardian reporting on data integrity in polling. In March 2026, researchers discovered that fraudulent church attendance data — generated by automated tools and paid survey participants — had contaminated polling datasets. The contamination was systematic enough to create false narratives about religious revival in Britain. [2]
Experts say paid participants are using automated tools to generate unreliable survey responses at scale.
The Guardian, 28 March 2026 [2]
The difference is instructive: the church data fraud was caught because it produced implausible results. EV numbers collapsing by 99.9 per cent should trigger the same alarm. It did not, because no one was checking.
What's Really Happening

The Real Stakes
The erosion of institutional data credibility has three cascading consequences.
First, decision-makers make bad calls. During an energy crisis, fuel price data that is off by orders of magnitude feeds into policy models. A government energy advisor using the RAC EV dataset would conclude that the electric vehicle transition has reversed catastrophically — prompting entirely wrong resource allocation. Confirmed: the fuel dataset was published during the current conflict in the Middle East when energy data directly shapes emergency planning. [1]
Second, trust in institutions evaporates. When citizens spot obvious errors in government data and nothing happens for a week, they conclude the institution is either incompetent or indifferent. Neither conclusion is recoverable. A fund manager reviewing UK energy infrastructure data will now discount government sources and rely instead on private vendors — increasing information asymmetry and cost. A policy advisor will hedge their recommendations because the underlying data is suspect.
Third, and most urgent: the AI feedback loop. The Guardian investigation documented how fraudulent survey data, once published, gets ingested into training datasets for language models. Those models then serve back the fraudulent patterns to new users, who treat the AI-generated output as validation of the original error. [2] The developer on Successful Software named this explicitly: I fear we are heading for a future where LLMs generate data, which people don't bother to properly check. This data is then used train LLMs. The error is then much harder to spot once it is served back without the original source by LLMs. A slop-apocalypse. [1]
This is not hypothetical. It is already happening. The contamination of church attendance data through AI-generated survey responses is the prototype. [2]
Industry Context
The root cause is not malice. It is institutional collapse of responsibility.
Data submission is decentralised: fuel stations enter their own prices; survey participants answer their own questions. This is unavoidable. But validation — the gate between raw input and publication — has been either eliminated or delegated to junior staff with no domain expertise or statistical training.
The RAC error (thousands vs. millions) suggests the graph was generated by someone who never looked at the output. The government's week-long non-response suggests no one owns the fuel dataset — it exists in limbo between departments, acknowledged but not claimed.
This is a staffing and accountability problem, not a technical one. Validation is not hard. It is boring. It is not rewarded. It is not celebrated. A data engineer who catches an error before publication gets no credit. A data engineer whose error reaches the public gets fired. The incentive structure is perverse.
Meanwhile, the pressure to publish at scale and speed is relentless. Government open data initiatives are measured by volume: how many datasets published, how many downloads. Quality is invisible in the metrics. RAC reports are measured by engagement: how many clicks, how many shares. A graph with an obvious error that triggers outrage performs better than a corrected one that nobody notices.

Impact Radar
Watch For
1. Does the UK government publish a corrected fuel dataset within 30 days, with a public statement on validation procedures? If not, it signals that data governance remains a non-priority even after public embarrassment. [1]
2. Do major news outlets (BBC, Financial Times, The Guardian) begin systematically fact-checking institutional datasets before citing them? If this becomes standard practice, it will force institutions to validate before publishing. If it does not, corrupted data will continue circulating unchecked.
3. Does any major AI lab (OpenAI, Anthropic, DeepMind) publish a framework for detecting and filtering contaminated training data? This is now urgent. The church data case proves the problem is live. [2]
Bottom Line
Institutions are publishing data without the most basic validation checks, then ignoring correction requests for weeks. This is not a technical problem — it is a governance failure. And because AI models now ingest this corrupted data at scale, the errors compound and become harder to trace. The fix is simple: hire people whose job is to ask "Does this make sense?" before anything goes live. The fact that this is not already standard practice is the real scandal.
---